
AI on Device
#라즈베리 파이 5에 LLaMA 올리기 (1/2) 본문
앞에서 실패를 향한 지루한 과정이 있었다.
망해봐야 보이는 것이 있고, 배우는 것이 있다. 물론 "망했다 !!"는 것을 깨우치기 전까지 투입된 시간과 노력이 정말 아깝지만, 이런 과정을 거쳐야 좋은 개발자가 될 것으로 본다.
- - - - -
hugging face에서 제시한 usage로는 메모리 부족 문제를 해결할 수 없었다. 우선 LLaMA2를 대상으로 fine tunning을 한 mistral / mixtral 계열은 사이즈가 LLaMA2 보다 크다. 문제는 또 있었다. 4bit quantization은 솔직히 말귀를 못알아 먹는다. 그럼에도 불구하고 4bit짜리라도 일단 올려보고 bit수를 올리는 작업을 하려고 한다. 그후에 quantization bit를 하나씩 올리는 수 밖에 없다. 그래도 안되면 그냥 손 놓고 기다리는 수 밖에 없다. 16 GB RAM을 장착하는 Raspberry pi 6든, 4bit로도 8bit quantization 성능에 근접하는 tunning을 한 것이든 말이다.
아무튼 개발자는 주어진 현실에서 최적은 아니더라도 최대의 성과를 내는게 목표이니...
LLaMA를 운용하기 위해 필요한 것들을 설치하고 나면 메모리 공간이 6.xxx GB 정도 여유밖에 없고, 여기에 .gguf로 나타나는 7B 모델을 올리는 것은 힘들다. 기본적으로 7B 모델을 설치하는데 적합한 메모리 공간은 14GB라고 한다. 따라서 좀 다른 방법을 찾아보게 되었다.
C++ 로 작성된 소스코드를 make해서 구조를 잡은 뒤에 pre-trained weight를 올려서 사용하는 방법외엔 없겠다는 결론이었다. 사실 문제는 git에서 어렵지 않게 찾을 수 있는 llama source code가 아니라 pretrained weight인데.....이거 찾는게 쉽지 않다. llama2가 나온 이후로 2024년 2월 25일 현재 mirror site들이 잠겨버렸기 때문이다.
#1. LLaMA open source로 간다.
open source 작업을 하려면 거쳐야 하는 99.9% 필연적인 길은 GITHUB을 이용해서 build 하는 것이겠지. 아래 순서대로 따라가보자.
| 명령어 | 설명 |
| sudo apt install git | git까지 길 뚫기 |
| sudo apt install g++ build-essential | C application을 설치하기 위해 G++와 build에 필요한 기본 설치 |
| git clone https://github.com/ggerganov/llama.cpp.git | llama 모델의 클로닝 |
| ***** python3 가상환경으로 들어가서 작업을 진행하자. | |
| python3 -m pip install torch numpy sentencepiece | pytorch, numpy, sentencepiece 설치 |
| ** 이제 llama build 를 해보자~ | 캬캬캬~ |
| cd llama.cpp | 클로닝한 llama.cpp로 들어가자. |
| make -j | 프로젝트 파일을 빌드하자. |
| 옆의 링크를 통해 LLaMA-7B torrent를 다운받을 수 있는데, 토렌트는 사용자가 닫아버릴 수도 있기 때문에 가능하면 아래 명령어를 사용해보자. |
여기까지 진행되었다면 반은 끝난 것이다.
참 쉽죠 잉~
#1.1 LLaMA.cpp ( https://github.com/ggerganov/llama.cpp 참조) 잠깐 들렸다 가기~
여기에서 LLaMA.cpp 를 사용하려는 몇가지 이유를 살펴보고, 몇가지 이해를 하고 가도록 하자.
github의 LLaMA 페이지( https://github.com/ggerganov/llama.cpp )에 들어가면 상세한 설명이 있는데, 그것을 참조해서 간단히 설명하자면,
llama.cpp의 목표는 LLM 추론을 수행하기 위한 최소한의 설정과 최신 성능을 클라우드나 단독 시스템에서 돌리기 위한 것으로 아래와 같다.
- 독립적인 C/C++로 구성되어 있다.
- ARM NEON 칩으로 최적화되어 있고, x86 아키텍쳐를 지원한다.
- 1.5bit, 2bit, 3bit, 4bit, 5bit, 6bit, 8bit의 정수로 양자화되어 있어 빠른 추론과 메모리 사용량이 적다.
- CUDA도 지원하고, AMD GPU(HIP의 도움을 받아서)도 지원한다.
- Vulkan, SYCL, OpenCL 백엔드도 지원한다.
- CPU+GPU를 함께 사용해서 추론이 되고, VRMA 용량보다 큰 모델도 부분적으로 가속이 가능하다.
뿐만 아니라, LLaMA를 기반으로 fine tunning을 수행한 여러 모델들도 지원한다. Mistral 7B, Mixtral MoE, Bloom, Phi Models, GPT-2, Gemma 등 쟁쟁한 모델들이 LLaMA를 기반으로 되어 있다. 멀티모달 모델로는 LLaVA 1.5, BakLLaVA, Obsidian, ShareGPT4V 등등.
우리가 사용하려고 하는 것은 7B 모델로서 아래와 같은 메모리 / 디스크 공간을 차지하게 된다. 8bit으로 quantization하는 경우 단순히 2배의 공간을 차지하는 것은 아니고, quantization method에 따라서도 달라지고 지속적으로 개선되기 때문에 2배 이하의 공간을 차지하는 것으로 생각할 수 있다.
| Original Size | 4bit quantized | |
| LLaMA-7B | 13GB | 3.9GB |
quantization 방법에 따라 차지하는 공간은 달라지므로 참조만 하자.
#1.2 무지성으로 LLaMA 다운받다 망하는 길
LLaMA.cpp에는 quantization과 parameter 수에 따라 몇가지 모델이 있는데, 그중에서 우리가 필요로 하는 것은 7B 모델과 관련된 파일 뿐이다. 전부다 받을 수 있겠지만 시간도 많이 걸리고, 무엇보다 파일 전부를 올려놓을 수가 없기 때문에 틀림없이 아래 그림처럼 "공간부족"이란 말을 보게 될 것이다. 사실 내가 사용하는 sdMicro가 128GB인데....그냥 꽉 차버렸다. 참고로 LLaMA.cpp 전부를 받으려면 220GB의 디스크 용량이 필요하다.
사실 512GB짜리 M.2 NVME를 사용하려고 했다가 HAT이 아직 들어오지 않아 할 수 없이 sdMicro를 그냥 사용중인데, 무지성으로 그냥 다운받았었다. 최종 fail까지 12시간이 넘게 걸렸다. 로그를 살펴보니......아래 그림과 같았다. ^^;; 써글. 개발자는 어떤 순간에도 무지성이 되면 안된다는 아픈 경험만 추가하고 말았다.

자 그럼 어떤 파일을 받아야 할까 ?
고민을 시작하기 전에 미리 Language Model을 테스트 해볼 수 있는 툴이 필요할 수 있는데, 그중에서 LM Studio를 알아보고 지나가기로 하자. 다른 툴들(LoLLMS Web UI, Faraday.dev 등)도 있으나, 개인적으로는 이 툴이 유용했다.
#1.3 LM Studio
LM Studio는 미리 이야기했어도 좋을 내용이다. 다른 툴도 있겠지만, 나는 이것을 주로 사용한다.
LM Studio는 주로 LLaMA기반의 Language Model을 미리 다운받아 windows 기반의 PC에서 사용해볼 수 있는 플랫폼이다. 사용법도 간단하다. 현재는 2.16까지 나왔는데, Google의 Gemma 모델까지 사용이 가능하다. 이런 플랫폼을 통해 평가해보고 적절한 용도의 Language Model을 받는 것도 좋다.

시작을 하면 아래 그림과 같이 나타난다. 필요하면 search를 통해 대상을 찾아 다운로드를 할 수 있고, AI chat으로 가서 해당 모델을 loading해서 써보면 된다.
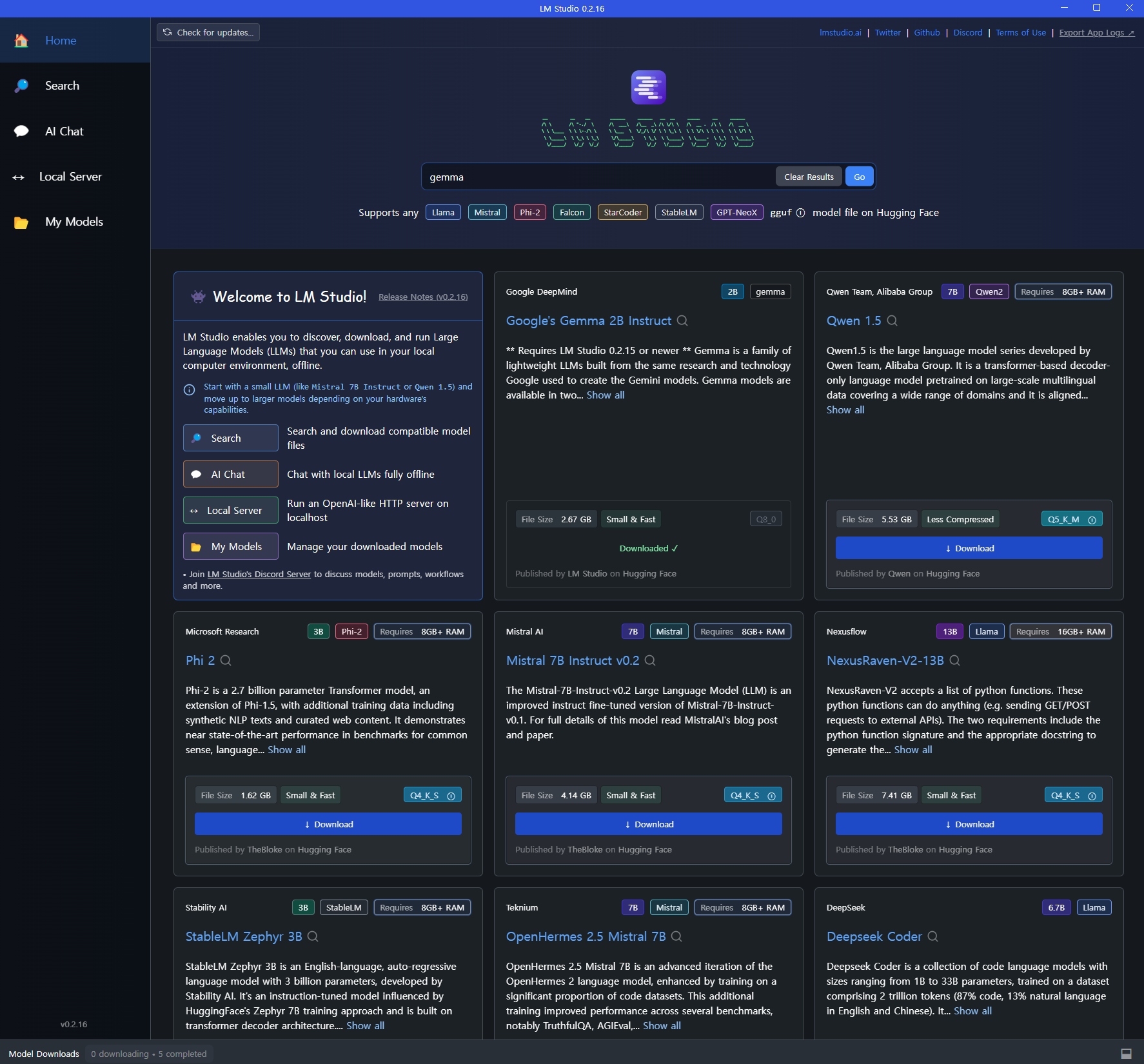
LLaMA2로 검색을 하면 아래와 같이 나타났다.

스튜디오의 아래측은 다운로드 받은 언어모델들을 나타내고, 좌측은 quantization을 제외한 fine tunning을 한 Languagwe Model의 list이다. 우측에서는 좌측에서 선택한 모델의 quantization(2bit, 4bit 등)에 따른 개별화된 최종 모델들을 보여준다.
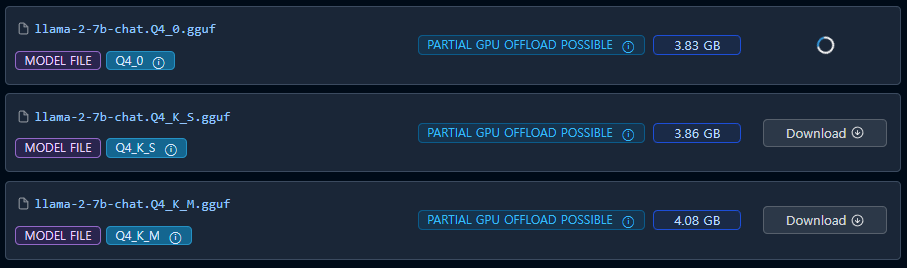
아래 그림은 4bit으로 quantization된 것들이다. Q4_0, Q4_K_S. Q4_K_M으로 나타난 것은 hugging face에서 파악해도 되고, 3개 전부 다운로드받아서 각각 평가를 해봐도 된다. 그중에 마음에 드는 것을 raspberry pi에 다운 받아서 사용하면 된다. 이렇게 보면 메모리 용량이 얼마되지 않는 7B 모델 대신 13B를 이와 같은 방법으로 사용해보면 될 것으로 본다.
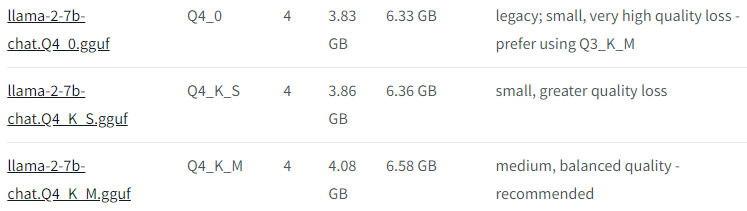
hugging face(https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF)에 있는 llama-2-7B-Q4 관련된 설명은 아래와 같다.
| Model Name | quant method | bit | Size | Max RAM required | Use Case |
AI chat 모드로 들어가서 상단에서 Language Model을 선택한다. 우측의 위도우는 펴치거나 접을 수 있는데, 몇가지 옵션을 선택할 수 있다. 특히 GPU를 사용하지 않거나 몇개 layer에서만 사용할 수 있도록 설정하고 평가를 진행할 수 있다. 아래 그림에서 보듯이 GPU는 사용하지 않고 있는데, CPU만으로도 별 불편은 느끼지 못했다.
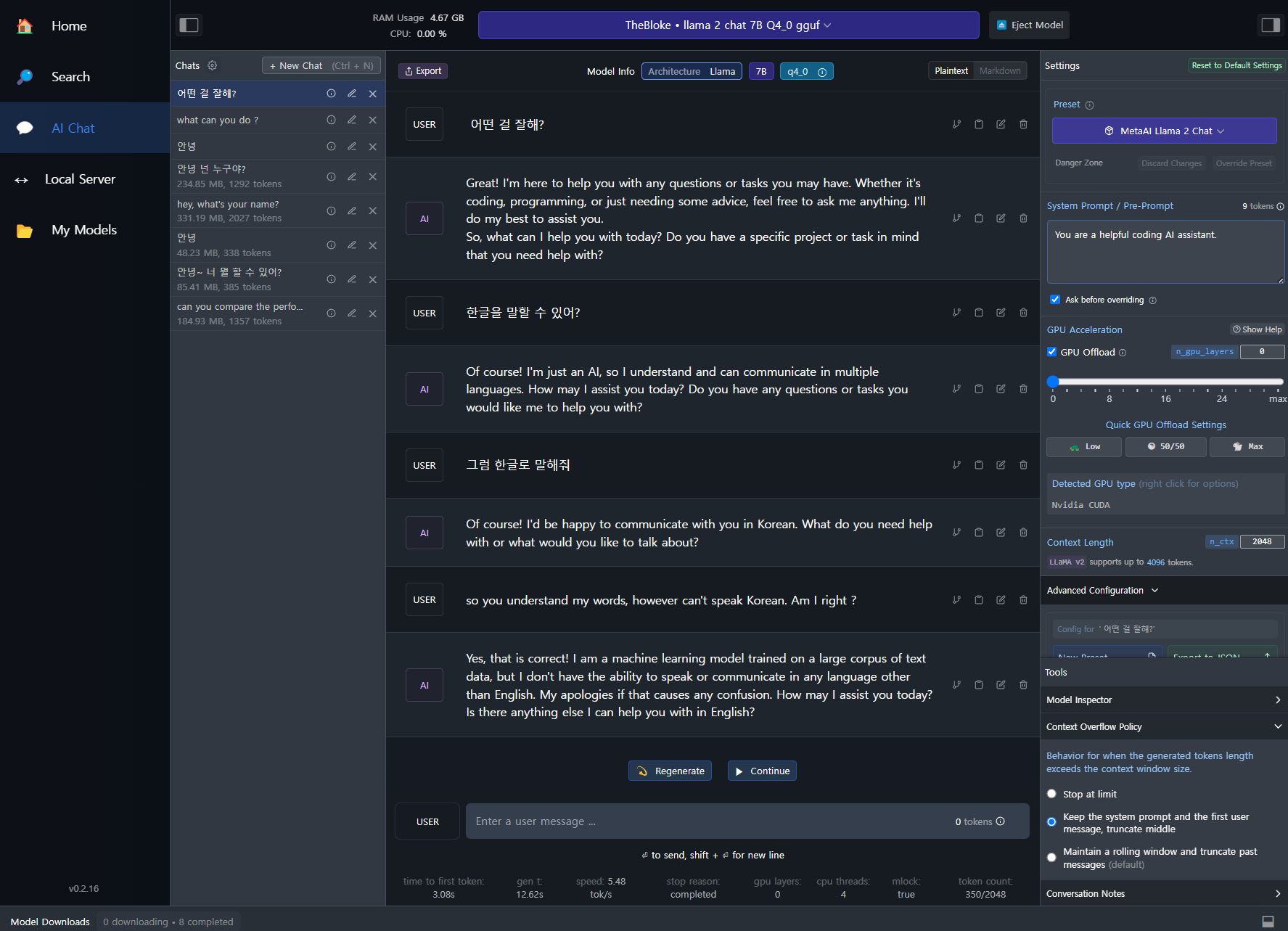
내 PC는 인텔 i5-9세대, 1060-6GB, 32GB RAM이다. HDD는 SSD라서 Language Model을 RAM에 loading할 때 속도가 좀 빠른 편이다. 이런 이유로 Raspberry pi 5에서도 M.2 NVME를 사용하지 않는 경우 loading 속도에서 좀 문제가 될 수 있다. 이는 customizing을 끝냈을 때, 부팅 속도 (loading 속도)를 보고 추후 결정하는 것이 좋을 것 같다. 현재 시점(2024년 2월 24일)에서 나도 아직 HAT을 받지 못해 3월 중순경에나 테스트해볼 수 있을 것 같고, sdMicro로롣 충분히 감당이 가능하다면 생산원가의 절감차원에서 굳이 SSD를 사용할 이유는 없을 것 같다.
#1.4 라즈베리파이5에 LLaMA 다운 받아보기
LLaMA가 quantization과 parameter 수에 따라 다양한 모델이 있다. 거기에 fune tunning을 한 모델들까지 합하면 수십개의 파생 모델들까지 있다. 우선, Base model을 사용해보면 좋을 것 같다.
한가지 주의할 점은 파일의 용량보다는 RAM에 loading했을 때의 용량이 크다는 점이다. Raspberry pi5의 RAM이 8GB라고 해도 시스템이 사용하거나 다른 어플리케이션을 올려서 사용해야할 때를 고려해야 하기 때문에 어림잡아 보아야 한다. 다만, Language 모델마다 차지하는 RAM 용량에 차이가 있다. base model의 파일 사이즈 x 2를 하면 가장 무난하다고 한다. 그러나, 라즈베리 파이5나 다른 소형 디바이스의 경우 메모리 사이즈가 넉넉허지 않기 때문에 빡빡하게 본다면 대략 70% 정도 추가하는 것이 맞고, base model에서 quantization을 통해 늘어난 용량에 대해서는 그만큼 더해주면 필요한 RAM 용량이 되는 것 같다.
이렇게 파일 사이즈와 메모리 사이즈를 보고나면 기본적으로 테스트할만한 것들과 도전이 필요한 영역이 있기 마련인데, 그건 각자 필요에 따라 판단하면 될 것 같다.
다만, 한가지 더 강조하고 싶은 것은....SSD이다. sdMicro로는 왠지 모르게 불안한 부분이 있다. 데이터 입출력 속도가 SSD와는 현저하게 차이가 있기 때문이다. 이전 포스트에서도 언급을 했었지만, 실제로 돌리다가 몇번을 사망했었던 것도 있지만, loading 속도가 정말 어마어마하다. 저녁 먹기전에 loading해두고 오면 꼭 죽어 있었다. ㅠ.
# LLaMA 2 Chat 7B@Q4_K_S ; 7B parameter에 4bit quantization
#2 라즈베리파이5에서 LLaMA 테스트 해보기
다운로드를 받고나서 TOP를 해보면 가용한 메모리가 아래와 같이 얼마 남지 않음을 알게 된다. 그래서 테스트를 진행하기 전에 reboot을 하도록 하자.

reboot을 하고나면 확실히 free memory의 용량이 커진 것을 알 수 있다. 주로 buffer/cache쪽에 메모리가 다운로드 받을 때 사용되었지만, 다운로드가 끝난 이후에 메모리가 반환되지 않았기 때문이다.
- - - - -
물론 Linux에서 사용하는 명령어가 있다.
sync
/proc/sys/vm/drop_cahches
근데, access denied.................................
crontab -e를 통해 작업을 해도 어차피 안되지 않을까? drop_caches를 사용하기 때문이다. 그래서, 그냥 reboot이 편하다. 조금 귀찮긴 하지만, 결과적으론 시간을 아껴준다는 느낌. 하지만, 개발자라면 솔루션을 찾아야지.
- - - - -
reboot후에 메모리는 대략 7GB 정도....

내가 테스트해 본 모델은 총 세가지로 llama2-7b-Q4_K_M.gguf, llama2-7b-Q4_K_S.gguf, llama2-7b-Q2_K.gguf 이다.
llama.cpp로 돌아가서 directory를 보면 실행파일로 main이 있다. 우리가 make한 binary 파일이다.
main 함수는 language model name과 "prompt 내용"을 입력하면 된다.
| ./main -m models/llama-2-7b-chat.Q4_K_S.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e |
| ./main -m models/codellama-7b-instruct.Q4_K_S.gguf -p "in python, write a function to create a Fibonacci sequence" -n 400 -e |
참고로....이 프롬프트를 실행하면서 두번이나 다운되어 버렸다. 원인을 찾다가 혹시나 해서 swap memory size를 조정했다.
swap memory default는 100MB인데, 2048MB로 좀 늘려봤었다. 그때부터 시스템 다운이 발생해서, 500MB로 줄이고 나서는 테스트에서 사망하지 않았다.......SSD를 설치했을 때 어떤 결과가 나올지 무척이나 궁금하기도 하다.
#3. interactive chat
chat 테스트를 위해서는 아래 코드를 넣어서 하면 된다.
| ./main -m models/llama-2-7b-chat.Q4_K_S.gguf --color \ --ctx_size 2048 \ -n -1 \ -ins -b 256 \ --top_k 10000 \ --temp 0.2 \ --repeat_penalty 1.1 |

사용해보다 보니 interactive chatting mode가 좀 더 안정적으로 동작을 하는 느낌이다. 아래 동영상은 실제 동작할 때 글자가 화면에 찍히는 스피드를 체감하라는 의미에서 덧붙인 것이니 참조하시기 바란다.
재미있는 점은 한글을 이해한다는 점이다. 그러나, 불행히도 한글 출력은 안된다.

#4. 테스트중 발생한 몇가지 주요 문제점
LLM은 라즈베리파이5의 메모리 뿐만 아니라 CPU에도 과부하를 걸어 버린다는 것은 익히 짐작이 가능하다. 다만, 나중에 문제점의 원인을 정확하게 파악하려면 multi-thread로 디버깅을 해봐야 할 것 같다. 씨리얼 포트 하나를 디버깅 용으로 빼 두긴 해야할 것 같다.
아무튼, 테스트 중에 원인을 가늠하기 힘든 문제가 두가지 정도 있었다.
# main function을 돌리면 전원 LED가 꺼지고 화면이 멈춘다.
과부하로 인해 라즈베리파이5의 LED 꺼진다. 전원이 나가는 경우 빨간색으로 변경되어야 하는데, 아무 동작도 안하는 듯이 꺼지는 것은.....CPU가 LED를 잠시라도 켤 여유가 없을 정도로 자원을 다 끌어다 사용한다는 의미로 생각한다. 화면도 함께 멈추는데, 처음에는 깜짝 놀래서 hard reset을 수행했었다. 몇번 겪고 나서야 CPU 자원의 문제라고 생각되었다.
아무튼 좀 기다리면 돌기 시작한다.
# 5V 5A 전원이 아니면 라즈베리파이5에 꽂힌 HDMI, USB 포트 등 연결된 것들을 빼주자.
위에서 잠깐 설명한 돌다가 멈추는 문제는 기다리면 해결되지만, 답변을 받가 말고 LED가 red로 변경되는 문제가 계속 되었는데, CPU에 과부하가 걸리는 문제 중 하나가 전력 부족이 또 다른 이유가 될 수도 있을 것 같았다. 내가 지금 사용하는 전원은 5V 3.5A 정도의 어댑터로 USB 포트마다 약 600mA(!)의 자원을 할당하는데, 이런 자원의 낭비적 할당이 CP 과부하시 적절한 전력을 공급하지 못하기 때문일 수도 있다.
즉.....remote로 VNC 대신 putty을 이용한 터미널 모드로 사용하는 것을 강력히 추천한다. 모....이미 그렇게들 사용하고 있겠지만~
- - - - - - -
....성능을 올리기 위해 어떤 방식이 더 필요할지 고민해봐야 할 것 같다. 소스코드를 make할 때, thread를 어떻게 설정할 수 있는지도 고민을 해봐야 할 것 같다. 끝.
- - - - - - -
'라즈베리 파이 5' 카테고리의 다른 글
| 라즈베리 파이 5에 LLM을 올리기 위한 개발설정(3) (0) | 2024.01.27 |
|---|---|
| 라즈베리 파이 5에 LLM을 올리기 위한 개발설정(2) (0) | 2024.01.27 |
| 라즈베리 파이 5에 LLM을 올리기 위한 개발설정(1) (2) | 2024.01.16 |


